about the "explicit extract from dataset" policy on the "train & validation" setting page.
I would like to be able to train a classification model with a balanced training set and run the test with an original (unbalanced) distribution test set. However, I realized that the records used for the training set are not automatically discarded to create the test set, and I did not find filters that allow such a task. Should I create training and test sets from notebook by myself or may exist a way that i didn't found?
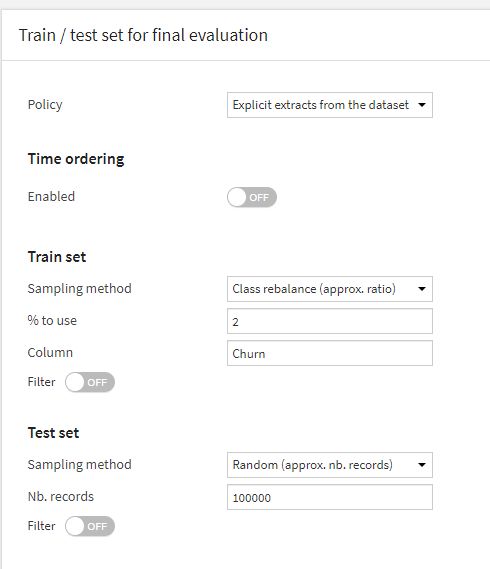
If I understood well you want to create a train and test set, have you tried in the settings of the model choose 'train and validation' and there change the policy to 'explicit extracts' and 'custome values subset' for sampling method?
Yes, in setting of the model i chosen 'train and validation', then 'explicit extracts' and later i chose for train sampling method 'class rebalance (ratio)' on my target variable.
Ath this point , for the sampling test method, there is no option to ensure that records in the training sample are excluded from the sample test
Can anyone confirm if we are using the explicit extract and class rebalance option so the train and test data set will be mutually exclusive? Thanks in advance.
What I did to split in the way I wanted is to do what I think you want is to use the filter option to filter the data sets and the train and test data sets did not repeat records. In my case I used the "customer lifetime value" data set to test this and used this method to split the train and test data set by gender. I received that I had a train dataset with 7876 rows and test set with 16923 rows. which are the same number of male and female registered rows respectively.
Let me know if this help, or if I didn't explain myself clearly so I can upload the screenshots I took so you can verify it.

{kind=link}